# 数组
# 创建数组
数组的创建方式:
- 方括号加元素内容
const arr = [1, 2, 3]
- 构造函数
const arr = new Array()
使用构造函数这种方式可以创建指定长度的数组。如下代码创建一个长度为7的数组。
const arr = new Array(7)
创建一个长度确定、同时每一个元素的值也都确定的数组
const arr = new Array(7).fill(1)
# 访问数组
可以直接通过索引访问数组元素
arr[0] // 访问索引下标为0的元素
# 数组的遍历
遍历数组的方法有很多,这里我们简单介绍下常用的三个
- for 循环
// 获取数组的长度
const len = arr.length
for(let i=0;i<len;i++) {
// 输出数组的元素值,输出当前索引
console.log(arr[i], i)
}
- forEach 方法
arr.forEach((item, index)=> {
// 输出数组的元素值,输出当前索引
console.log(item, index)
})
- map 方法
map 方法会根据传入的函数逻辑对数组中每个元素进行处理、进而返回一个全新的数组。
const newArr = arr.map((item, index)=> {
// 输出数组的元素值,输出当前索引
console.log(item, index)
// 在当前元素值的基础上加1
return item+1
})
# 二维数组
下面是一个二维数组
const arr = [
[1,2,3,4,5],
[1,2,3,4,5],
[1,2,3,4,5],
[1,2,3,4,5],
[1,2,3,4,5]
]
在数学中,形如这样长方阵列排列的复数或实数集合,被称为“矩阵”。因此二维数组的别名就叫“矩阵”。
# 二维数组的初始化
推荐的初始化二维数组的方法:
const len = arr.length
for(let i=0;i<len;i++) {
// 将数组的每一个坑位初始化为数组
arr[i] = []
}
错误示范:
const arr =(new Array(7)).fill([])
这样乍一看好像没错,但是实际是有问题的
arr[0][0] = 1

会发现一整列的元素都被设为了 1
这是因为当给fill 传递一个入参时,如果这个入参的类型是引用类型,那么 fill 在填充坑位时填充的其实就是入参的引用。
上例中的7个数组对应了同一个引用、指向的是同一块内存空间,它们本质上是同一个数组。当修改第0行第0个元素的值时,第1-6行的第0个元素的值也都会跟着发生改变。
# 栈和队列
在JS中我们可以通过数组来实现栈和队列。这里我们先来简单看下数组中增删操作(下面的操作都会改变原数组):
数组中增加元素的三种方法
- unshift 方法 - 可向数组的开头添加一个或更多元素,并返回新的长度
const arr = [1,2]
arr.unshift(0) // [0,1,2]
- push 方法 - 添加元素到数组的尾部,并返回新的长度
const arr = [1,2]
arr.push(3) // [1,2,3]
- splice 方法 - 添加元素到数组的指定位置
const arr = [1,2]
arr.splice(1,0,3) // [1,3,2]
数组中删除元素的三种方法
- shift 方法 - 删除数组头部的元素,并返回删除的元素
const arr = [1,2,3]
arr.shift() // [2,3]
- pop 方法 - 删除数组尾部的元素,并返回删除的元素
const arr = [1,2,3]
arr.pop() // [1,2]
- splice 方法 - 删除数组指定位置的元素,并返回删除的元素的数组
const arr = [1, 2, 3]
console.log(arr.splice(0, 1)) // [1]
上面你可能会有疑惑,咦 splice 这个方式是既可以删除元素也可以添加元素的吗,是的,这里简单介绍下 splice 方法。
语法:
arrayObject.splice(index,howmany,item1,.....,itemX)
参数:
- index 必需。整数,规定添加/删除项目的位置,使用负数可从数组结尾处规定位置。
- howmany 必需。要删除的项目数量。如果设置为 0,则不会删除项目。
- item1, ..., itemX 可选。向数组添加的新项目。
返回值:
包含被删除项目的新数组,如果有的话。
从用法可以看出,如果 splice 的第二个参数设置为零,并设置了第三个参数,就会向数组中添加元素,返回结果是一个空数组。
# 栈
栈是一种后进先出(LIFO,Last In First Out)的数据结构。它有两个特征:
- 只允许从尾部添加元素
- 只允许从尾部取出元素
在JS中我们可以使用数组的pop和push方法来实现栈这种数据结构。
// 初始状态
const stack = []
// 入栈
stack.push('1')
stack.push('2')
stack.push('3')
stack.push('4')
// 出栈
while(stack.length) {
// 访问栈顶元素
const top = stack[stack.length - 1]
console.log('栈顶为', top)
// 栈顶元素出栈
stack.pop()
}
# 队列
队列是一种先进先出(FIFO,First In First Out)的数据结构。它有两个特征:
- 只允许从尾部添加元素
- 只允许从头部移除元素
在JS中我们可以通过数组的 push 和 shift 方法来实现队列这种数据结构。
const queue = []
queue.push('1')
queue.push('2')
queue.push('3')
queue.push('4')
while(queue.length) {
// 访问队首元素
const top = queue[0]
console.log('队首元素为', top)
// 队首元素出队
queue.shift()
}
# 链表
数组在内存中最为关键的一个特征,就是它一般是对应一段位于自己上界和下界之间的、一段连续的内存空间。
链表中的结点,可能是散落在内存空间的各个角落里。
在链表中,每一个结点的结构都包括了两部分的内容:数据域和指针域。JS中的链表,是以嵌套的对象的形式实现的:
{
// 数据域
val: 1,
// 指针域,指向下一个结点
next: {
val:2,
next: ...
}
}
数据域存储的是当前结点所存储的数据值,而指针域则代表下一个结点(后继结点)的引用。

当访问链表中的某个节点时,需要从链表的头节点开始逐个访问next,一直访问到目标节点位置。
# 链表结点的创建
function ListNode(val) {
this.val = val;
this.next = null;
}
const node = new ListNode(1)
node.next = new ListNode(2)
上述代码创建出了一个数据域值为1,next 结点数据域值为2的链表结点:

# 链表元素的添加
在链表末尾添加元素
function ListNode(val) {
this.val = val
this.next = null
}
const node1 = new ListNode(1)
node1.next = new ListNode(2)
node1.next.next = new ListNode(3)
 在链表中间添加元素
在链表中间添加元素
function ListNode(val) {
this.val = val
this.next = null
}
const node1 = new ListNode(1)
node1.next = new ListNode(2)
const node3 = new ListNode(3)
node3.next = node1.next
node1.next = node3
插入前
 插入后
插入后

# 链表元素的删除
注意
在删除链表中节点时,重点是定位目标结点的前驱结点。
这里以删除上例中node3节点为例。
删除的方法是直接让它的前驱结点 node1 的 next 指针跳过它、指向 node3 的后继,让其不可能被遍历到,它会被 JS 的垃圾回收器自动回收掉

function ListNode(val) {
this.val = val
this.next = null
}
const node1 = new ListNode(1)
node1.next = new ListNode(2)
const node3 = new ListNode(3)
node3.next = node1.next
node1.next = node3
// 删除node3
node1.next = node3.next
# 链表和数组的辨析
我们假设数组的长度是 n,那么因增加/删除操作导致需要移动的元素数量,就会随着数组长度 n 的增大而增大,呈一个线性关系。所以说数组增加/删除操作对应的复杂度就是 O(n)
链表的优点:添加和删除元素都不需要挪动多余的元素。链表增删操作的复杂度是常数级别的复杂度,用大 O 表示法表示为 O(1)
链表的弊端:在访问链表中某个节点时,必须遍历整个链表来查找它。
// 记录目标结点的位置
const index = 10
// 设一个游标指向链表第一个结点,从第一个结点开始遍历
let node = head
// 反复遍历到第10个结点为止
for(let i=0;i<index&&node;i++) {
node = node.next
}
因此访问链表中指定节点的复杂度为O(n)。而数组因为可以通过索引直接访问指定元素,所以访问数组中指定位置的元素的复杂度为O(1)。
还要注意,在真正的数组定义中,都有一个“存储在连续的内存空间里”这样的必要条件。但因为JS中的数组可以存储任何类型的值,所以JS中的数组不一定是连续的内存,如下:
const arr = ['haha', 1, {a:1}]
上面这个数组对应的是一段非连续的内存。此时,JS 数组不再具有数组的特征,其底层使用哈希映射分配内存空间,是由对象链表来实现的。
# 树
# 理解树结构
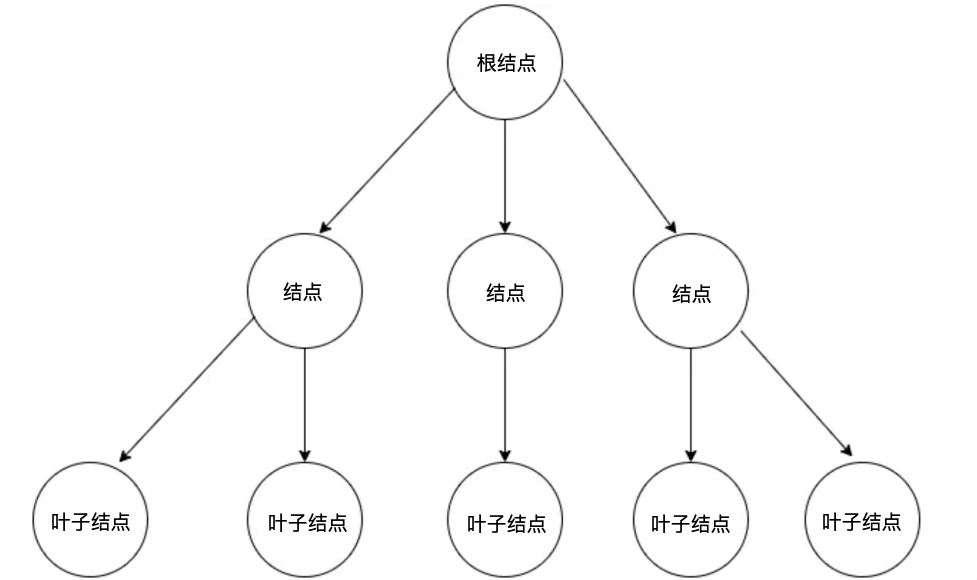
这里需要牢记以下几个树的关键特性和重点概念
- 树的层次计算规则:根结点所在的那一层记为第一层,其子结点所在的就是第二层,以此类推
- 结点和树的高度计算规则:叶子结点高度计为1,每向上一层高度就加1,逐层向上累加至目标时,所得到的值就是目标节点的高度。树中节点的最大高度,称为树的高度。
- 度的概念:一个结点开叉出去多少个子树,被记为结点的度。上图中,根结点的度就是3。
- 叶子结点:叶子节点就是度为零的结点。上图中,最后一层的结点的度全部为0,所以这一层的结点都是叶子结点。
# 理解二叉树结构
注意
二叉树不能被简单定义为每个结点的度都是2的树。普通的树并不会区分左子树和右子树,但在二叉树中,左右子树的位置是严格约定、不能交换的。
二叉树需要满足以下条件:
- 它可以没有根节点,作为一棵空树存在
- 如果它不是空树,那么必须由根结点、左子树和右子树组成,且左右子树都是二叉树。
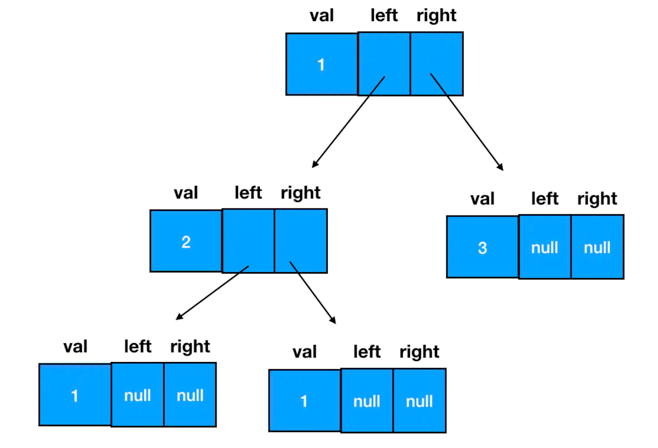
# 二叉树的编码实现
在JS中二叉树使用对象来定义,这个对象由三部分组成:
- 数据域
- 左侧子结点(左子树根结点)的引用
- 右侧子结点(右子树根结点)的引用
代码实现:
// 二叉树结点的构造函数
function TreeNode(val) {
this.val = val;
this.left = this.right = null;
}
const node = new TreeNode(1)
一棵二叉树的实际形态: